What is Data Science?
As per wikipedia
Data science, also known as data-driven science, is an interdisciplinary field about scientific methods, processes, and systems to extract knowledge or insights from data in various forms, either structured or unstructured, similar to data mining.
Well that makes sense, if you already know what is data science. Let me elaborate on that a little.
Data Science is an umbrella term for a lot of different scientific and engineering fields combined to solve data centric problems like business problems or finance problems and to develop data driven products.
Data Science combines various fields like mathematics, data analytics, data mining, programming, machine learning, big data, database technologies.
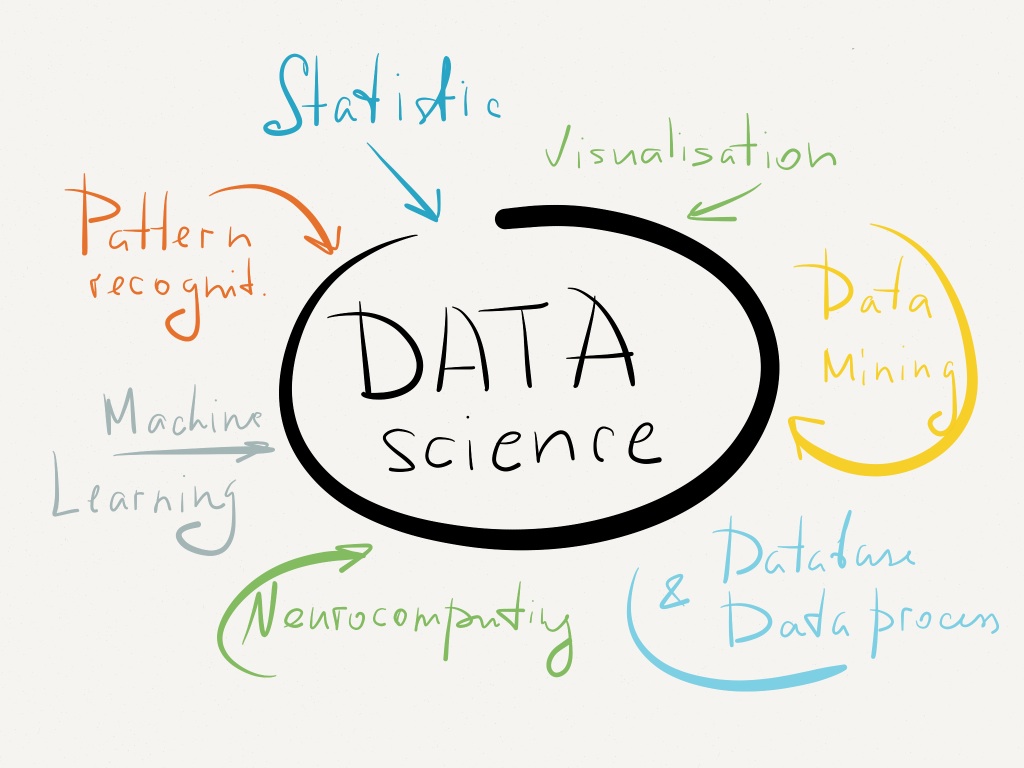
You must be like WOAH, slow down buddy. I know these are lot of fields, that’s why data scientist are in so much demand and data scientist is the SEXIEST JOB OF 21st CENTURY.
Let’s define and explore some of the above mentioned terms that all people might not be familiar with.
Data Analysis
Data Analysis is the process of collecting, cleaning, modelling data to extract patterns and to perform prediction using the data.
Data Analysis process is very similar to Data Science process which I will be explaining in later section of this article.
Data Mining
According to wikipedia
Data mining is the computing process of discovering patterns in large datasets involving methods at the intersection of machine learning, statistics, and database systems. An essential process where intelligent methods are applied to extract data patterns. The overall goal of the data mining process is to extract information from a data set and transform it into an understandable structure for further use. Aside from the raw analysis step, it involves database and data management aspects, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualisation, and online updating.
Data Mining simply in a nutshell is a data analysis technique that primarily focuses on the prediction aspect of data analysis. Data Mining is generally performed on Data Warehouses. Data Warehouses are special type of set of databases that are made for the purpose of knowledge extraction to aid in decision making. They are specialised and optimised for Bulk operations. For more in-depth understanding of Data Warehouses see this post.
For understanding above mentioned terms in more depth or the terms that I left out visit my blog for more in-depth articles.
To know the skillset for a Data Scientist read this post.
Data Science Process
Data Collection
One of the heavy task in data science process is the data collection part because there are large of data sources with varying size, format and level of difficulty in extraction.
Few of these sources includes:
Internet: Various sources from Internet includes websites, social media, APIs, emails etc.. Data extraction from websites is done by web scraping. Difficulty of web scraping depends on amount of effort put in by the website creators to avoid scraping. Social Media data is easily available nowadays for few platforms through APIs.
Flat Files: These resources are mostly used for practise because these sources are not good enough to perform large scale analysis. Most of the data is generated on Internet, but there is still data that comes in the form for flat files like survey data or data created by various employees in a organisation. These sources includes files like JSON files, CSV files, Excel and XML files.
Databases: Databases is a big source for data analysis. Every organisation’s data resides in databases. It is a gold mine for structured data, but quantity of data makes it difficult to create and train really useful models like deep learning models. There are 2 types of database management systems SQL and NoSQL DBMS.
SQL databases includes MySQL, PostgreSQL etc and NoSQL dbms includes MongoDB, Cassandra. To know more about the differences between see this post.
Other sources includes server log files, binary files like pdf files and sensor data etc..
Data Prepartion
This step includes preprocessing of collected data to make it suitable for processing. Data preparation is the most time consuming phase of data science process. Quality of data heavily influence training and prediction of our machine learning models.
Data Cleaning: It is the process of handling missing data, erroneous data and data inconsistencies.
There are various techniques to handle missing data. Actual technique to pick depends on our dataset. For example we can either avoid missing values or fill in using mean or interpolation.
Data Transformation: Data transformation techniques like merging, grouping, shifting, aggregating, transforming to make data more suitable to perform data analysis. In real world data may be divided into different datasets and we may need to merge them to make a dataset which is suitable for answering the questions that are asked.
EDA
EDA stands for Exploratory Data Analysis. The motive behind EDA is to understand our data better. EDA is used to explore and understand data which helps us in next phase of data science process i.e. modelling. To choose a machine learning model we need to understand questions being asked and nature of data. EDA helps in summarising the data using descriptive analysis and inferential analysis helps us in understanding distribution of data and relationship between different features of data.
EDA includes:
Visualisation: Visualisation is a great way to get an intuitive understanding of our data. Various different plot are used to visualise like box plot, line plot, scatter plot etc. For more visualisation in data science see this post.
Descriptive Analysis: It is used to describe our data and understand the broader patterns in our data using descriptive statistics. It includes measuring of central tendencies and central deviations.
Confirmatory Analysis: In this analysis we use inferential statistics to find relation between various features of dataset. We use techniques like hypothesis testing and different tests like p-test, chi-square test.
Modelling
Modelling is the process of creating statistical or machine learning models to fit our data. There are two types of modelling i.e. statistical modelling and machine learning modelling. These models are used to do predictions. It involves various steps, more like a cycle
Model Selection: In this step we choose set of models depending on our data and EDA, to model our data. We want to pick multiple algorithms because one model might have better performance or/and accuracy in our dataset.
Training: In this step we train our model using our data. We divide our dataset into training data and testing data. Technique like cross validation can be used to divide our data into training and testing data. Training data is used to train our model.
Testing/Evaluation: After training we test our model using testing data.
This cycle is repeated until desired accuracy and performance is received or pick another model or combine multiple models to suit our data.
Finally after modelling we either build our data-driven products by integrating our models in these applications, this process is called model deployment, or we communicate our findings by reports and visualisations.
